【原创】2019.10.08
TensorFlow 是一个采用数据流图(data flow graphs),用于数值计算的开源软件库。
节点(Nodes)在图中表示数学操作,图中的线(edges)则表示在节点间相互联系的多维数据数组,即张量(tensor)。它灵活的架构让你可以在多种平台上展开计算,例如台式计算机中的一个或多个CPU(或GPU),服务器,移动设备等等。
TensorFlow 最初由Google机器智能研究机构的研究员和工程师们开发出来,用于机器学习和深度神经网络方面的研究,但这个系统的通用性使其也可广泛用于其他计算领域。Google不仅是大数据和云计算的领导者,在机器学习和深度学习上也有很好的实践和积累,在2015年年底开源了内部使用的深度学习框架TensorFlow。
与Caffe、Theano、Torch、MXNet等框架相比,TensorFlow在Github上Fork数和Star数都是最多的,而且在图形分类、音频处理、推荐系统和自然语言处理等场景下都有丰富的应用。最近流行的Keras框架底层默认使用TensorFlow,著名的斯坦福CS231n课程使用TensorFlow作为授课和作业的编程语言,国内外多本TensorFlow书籍已经在筹备或者发售中,AlphaGo开发团队Deepmind也计划将神经网络应用迁移到TensorFlow中,这无不印证了TensorFlow在业界的流行程度。
经过我自己拍摄图片、标记图片、生成记录、训练、导出数据、运行程序截图如下:


该文档是有关如何使用TensorFlow的对象检测API来针对Windows 10、8或7上的多个对象训练对象检测分类器的教程。)使用TensorFlow 1.5版编写,但也适用于TensorFlow的较新版本。
本自述文件介绍了使用自己的对象检测分类器所需的每个步骤:
- 安装Anaconda,CUDA和cuDNN
- 设置对象检测目录结构和Anaconda虚拟环境
- 收集和标记图片
- 生成训练数据
- 创建标签图并配置培训
- 训练
- 导出推理图
- 测试和使用新近训练过的物体检测分类器
附录:常见错误
该教程提供训练“ Pinochle Deck”纸牌检测器所需的所有文件,该检测器可以精确检测9点,10点,K,Q和A。本教程介绍了如何用您自己的文件替换这些文件,以训练您的想要的检测分类器。它还具有Python脚本,可以在图像,视频或网络摄像头feed上测试分类器。
本教程的目的是说明如何从头开始为多个对象训练自己的卷积神经网络对象检测分类器。在本教程的最后,您将拥有一个程序,该程序可以在图片,视频或网络摄像头feed中的特定对象周围识别并绘制框。
关于如何使用TensorFlow的对象检测API来训练单个对象的分类器,有很多不错的教程可用。但是,这些通常假定您使用的是Linux操作系统。如果您像我一样,可能会有点犹豫,请在您的高性能游戏PC上安装Linux,该PC上装有用于训练分类器的高端显卡。对象检测API似乎是在基于Linux的操作系统上开发的。要设置TensorFlow在Windows上训练模型,需要使用几种解决方法来代替在Linux上可以正常使用的命令。另外,本教程还提供了训练分类器的说明,该分类器可以检测多个对象,而不仅仅是一个。
该教程是针对Windows 10编写的,也将适用于Windows 7和8。该常规过程也可用于Linux操作系统,但是文件路径和软件包安装命令将需要相应更改。我在编写本教程的初始版本时使用了TensorFlow-GPU v1.5,但它可能会在TensorFlow的未来版本中使用。
TensorFlow-GPU允许您的PC在训练时使用视频卡提供额外的处理能力,因此将在本教程中使用它。以我的经验,使用TensorFlow-GPU而不是常规的TensorFlow将训练时间减少了大约8倍(训练是3个小时,而不是24个小时)。TensorFlow的纯CPU版本也可以用于本教程,但是会花费更长的时间。如果您使用仅CPU的TensorFlow,则无需在步骤1中安装CUDA和cuDNN。
1.安装Anaconda,CUDA和cuDNN
按照YouTube视频,其中显示了安装Python,CUDA和cuDNN过程。您无需实际安装视频中所示的TensorFlow,因为我们将在步骤2中稍后进行安装。该视频是为TensorFlow-GPU v1.4制作的,因此请下载并安装最新TensorFlow版本的CUDA和cuDNN版本。 ,而不是视频中指示的CUDA v8.0和cuDNN v6.0。该TensorFlow网站表示这是需要TensorFlow的最新版本CUDA和cuDNN的版本。
如果您使用的是TensorFlow的旧版本,请确保使用与所使用的TensorFlow版本兼容的CUDA和cuDNN版本。下表显示了哪个TensorFlow版本需要哪个版本的CUDA和cuDNN。
请确保按照视频中的说明安装Anaconda,因为本教程的其余部分将使用Anaconda虚拟环境。(注意:当前版本的Anaconda使用的是Python 3.7,TensorFlow并未正式支持它。但是,在本教程的步骤2d中创建Anaconda虚拟环境时,我们将告诉它使用Python 3.5。)
请访问TensorFlow的网站以获取更多安装详细信息,包括如何在其他操作系统(例如Linux)上进行安装。该物体检测库本身也有安装说明。
2.设置TensorFlow目录和Anaconda虚拟环境
TensorFlow对象检测API需要使用其GitHub存储库中提供的特定目录结构。它还需要几个其他的Python程序包,对PATH和PYTHONPATH变量的特定添加,以及一些额外的设置命令,以设置一切以运行或训练对象检测模型。
本教程的这一部分介绍了所需的全部设置。这是非常细致的,但是请严格按照说明进行操作,因为不正确的设置会导致繁琐的错误。
2a。从GitHub下载TensorFlow对象检测API存储库
直接在C:中创建一个文件夹,并将其命名为“ tensorflow1”。该工作目录将包含完整的TensorFlow对象检测框架,以及您的训练图像,训练数据,训练有素的分类器,配置文件以及对象检测分类器所需的所有其他内容。
单击“克隆或下载”按钮并下载zip文件,下载位于https://github.com/tensorflow/models的完整TensorFlow对象检测存储库。打开下载的zip文件,然后将“ models-master”文件夹直接解压缩到您刚创建的C:\ tensorflow1目录中。将“ models-master”重命名为“ models”。
注意:TensorFlow模型存储库的代码(包含对象检测API)由开发人员不断更新。有时,他们进行更改会破坏旧版TensorFlow的功能。始终最好使用最新版本的TensorFlow并下载最新的模型存储库。如果您使用的不是最新版本,请克隆或下载所使用版本的提交,如下表所示。
如果您使用的是TensorFlow的旧版本,则下表显示了应使用的存储库的GitHub提交。我通过转到模型存储库的发布分支并在分支的最后一次提交之前获得提交来生成此文件。(在创建正式版本之前,他们将研究文件夹作为最后的提交删除。)
本教程最初使用TensorFlow v1.5和TensorFlow对象检测API的GitHub提交完成。如果本教程的某些部分不起作用,则可能有必要安装TensorFlow v1.5并使用此确切的提交而不是最新的版本。
2b。从TensorFlow的模型库下载Faster-RCNN-Inception-V2-COCO模型
TensorFlow在其模型库中提供了几种对象检测模型(具有特定神经网络架构的预训练分类器)。某些模型(例如SSD-MobileNet模型)具有允许更快检测但精度较低的体系结构,而某些模型(例如Faster-RCNN模型)给出的检测速度较慢但精度更高。我最初是从SSD-MobileNet-V1模型开始的,但是在识别图像中的卡方面做得并不出色。我在Faster-RCNN-Inception-V2模型上对检测器进行了重新训练,检测效果明显更好,但速度明显降低。
您可以选择训练异物检测分类器所基于的模型。如果您打算在计算能力较低的设备(例如智能手机或Raspberry Pi)上使用对象检测器,请使用SDD-MobileNet模型。如果要在功能强大的笔记本电脑或台式PC上运行检测器,请使用RCNN模型之一。
本教程将使用Faster-RCNN-Inception-V2模型。在此处下载模型。使用诸如WinZip或7-Zip之类的文件存档器打开下载的fast_rcnn_inception_v2_coco_2018_01_28.tar.gz文件,并将faster_rcnn_inception_v2_coco_2018_01_28文件夹解压缩至C:\ tensorflow1 \ models \ research \ object_detection文件夹。(注意:型号日期和版本将来可能会更改,但仍可在本教程中使用。)
2c。从GitHub下载本教程的资源库
下载位于此页面上的完整存储库(滚动到顶部,然后单击克隆或下载),然后将所有内容直接解压缩到C:\ tensorflow1 \ models \ research \ object_detection目录中。(您可以覆盖现有的“ README.md”文件。)这将建立一个特定的目录结构,该结构将用于本教程的其余部分。
此时,这是\ object_detection文件夹的外观:
该存储库包含训练“ Pinochle Deck”纸牌检测器所需的图像,注释数据,.csv文件和TFRecords。您可以使用这些图像和数据练习制作自己的Pinochle卡检测器。它还包含用于生成训练数据的Python脚本。它具有用于测试图像,视频或网络摄像头订阅源上的对象检测分类器的脚本。您可以忽略\ doc文件夹及其文件;它们只是保存用于此自述文件的图像。
如果您想练习训练自己的“ Pinochle Deck”卡检测器,则可以保留所有文件。您可以按照本教程进行操作,以了解如何生成每个文件,然后进行培训。您仍然需要按照步骤4中所述生成TFRecord文件(train.record和test.record)。
您还可以从此Dropbox链接下载经过训练的Pinochle Deck卡检测器的冻结推理图,并将内容提取到\ object_detection \ inference_graph。该推断图将“开箱即用”。您可以通过运行Object_detection_image.py(或视频或网络摄像头)脚本,在完成步骤2a-2f中的所有设置说明后进行测试。
如果要训练自己的对象检测器,请删除以下文件(不要删除文件夹):
- \ object_detection \ images \ train和\ object_detection \ images \ test中的所有文件
- \ object_detection \ images中的“ test_labels.csv”和“ train_labels.csv”文件
- \ object_detection \ training中的所有文件
- \ object_detection \ inference_graph中的所有文件
现在,您准备从头开始训练自己的物体检测器。本教程将假定删除上面列出的所有文件,并继续说明如何为您自己的训练数据集生成文件。
2d。设置新的Anaconda虚拟环境
接下来,我们将在Anaconda中为tensorflow-gpu设置虚拟环境。在Windows的“开始”菜单中,搜索Anaconda Prompt实用程序,右键单击该实用程序,然后单击“以管理员身份运行”。如果Windows询问您是否要允许它对计算机进行更改,请单击“是”。
在弹出的命令终端中,通过发出以下命令来创建一个名为“ tensorflow1”的新虚拟环境:
C:\> conda create -n tensorflow1 pip python=3.5
然后,通过发出以下命令激活环境并更新点值:
C:\> activate tensorflow1
(tensorflow1) C:\>python -m pip install --upgrade pip
通过发出以下命令在此环境中安装tensorflow-gpu:
(tensorflow1) C:\> pip install --ignore-installed --upgrade tensorflow-gpu
(注意:您也可以使用TensorFow的仅CPU版本,但运行速度会慢得多。如果要使用仅限CPU的TensorFow,只需在上一个命令中使用“ tensorflow”而不是“ tensorflow-gpu”即可。 )
通过发出以下命令来安装其他必要的软件包:
(tensorflow1) C:\> conda install -c anaconda protobuf
(tensorflow1) C:\> pip install pillow
(tensorflow1) C:\> pip install lxml
(tensorflow1) C:\> pip install Cython
(tensorflow1) C:\> pip install contextlib2
(tensorflow1) C:\> pip install jupyter
(tensorflow1) C:\> pip install matplotlib
(tensorflow1) C:\> pip install pandas
(tensorflow1) C:\> pip install opencv-python
(注意:TensorFlow不需要'pandas'和'opencv-python'软件包,但是它们在Python脚本中用于生成TFRecords以及处理图像,视频和网络摄像头feed。)
2e。配置PYTHONPATH环境变量
必须创建一个指向\ models,\ models \ research和\ models \ research \ slim目录的PYTHONPATH变量。通过发出以下命令(从任何目录)来执行此操作:
(tensorflow1) C:\> set PYTHONPATH=C:\tensorflow1\models;C:\tensorflow1\models\research;C:\tensorflow1\models\research\slim
(注意:每次退出“ tensorflow1”虚拟环境时,都会重置PYTHONPATH变量并需要重新设置。您可以使用“ echo%PYTHONPATH%”来查看它是否已设置。)
2f。编译Protobufs并运行setup.py
接下来,编译Protobuf文件,TensorFlow使用该文件来配置模型和训练参数。不幸的是,发布在TensorFlow的“对象检测API” 安装页面上的简短协议编译命令在Windows 上不起作用。\ object_detection \ protos目录中的每个.proto文件都必须由命令单独调出。
在Anaconda命令提示符中,将目录更改为\ models \ research目录:
(tensorflow1) C:\> cd C:\tensorflow1\models\research
然后将以下命令复制并粘贴到命令行中,然后按Enter:
protoc --python_out=. string_int_label_map.proto
这将从\ object_detection \ protos文件夹中的每个name.proto文件创建一个name_pb2.py文件。
(注意:TensorFlow有时会向\ protos文件夹中添加新的.proto文件。如果收到错误消息ImportError:无法导入名称'something_something_pb2',则可能需要更新protoc命令以包括新的.proto文件。)
最后,从C:\ tensorflow1 \ models \ research目录运行以下命令:
(tensorflow1) C:\tensorflow1\models\research> python setup.py build
(tensorflow1) C:\tensorflow1\models\research> python setup.py install
2g. 测试TensorFlow设置以验证其是否有效
现在,所有TensorFlow对象检测API都已设置为使用预训练的模型进行对象检测,或训练新模型。您可以通过使用Jupyter启动object_detection_tutorial.ipynb脚本来进行测试并验证安装是否正常。从\ object_detection目录,发出以下命令:
(tensorflow1) C:\tensorflow1\models\research\object_detection> jupyter notebook object_detection_tutorial.ipynb
这将在默认的Web浏览器中打开脚本,并允许您一次单步执行代码。您可以通过单击上方工具栏中的“运行”按钮来逐步浏览每个部分。当该部分旁边的“ In [*]”文本中填充数字(例如“ In [1]”)时,该部分运行完毕。
(注意:脚本的一部分从GitHub下载ssd_mobilenet_v1模型,大约74MB。这意味着需要一些时间来完成本节,因此请耐心等待。)
逐步完成脚本后,您应该在页面底部看到两个带有标签的图像。如果看到此消息,则说明一切正常!如果没有,底部将报告遇到的任何错误。有关设置时遇到的错误列表,请参见附录。
注意:如果运行完整的程序时未出现任何错误,但仍未显示带标签的图片,请尝试以下操作:进入object_detection / utils / visualization_utils.py并注释掉第29和30行周围的import语句,其中包括matplotlib。然后,尝试重新运行程序。
3.收集并标记图片
现在已经完成TensorFlow对象检测API的所有设置并可以使用了,我们需要提供用于训练新的检测分类器的图像。
3a。收集图片

TensorFlow需要一个对象的数百张图像来训练一个好的检测分类器。为了训练鲁棒的分类器,训练图像应在图像中具有随机对象以及所需对象,并应具有各种背景和光照条件。应该有一些图像,其中所需物体被部分遮挡,与其他物体重叠或仅在图片的一半位置。
对于我的Pinochle卡检测分类器,我有六个要检测的对象(卡的排名为九,十,Q,King和A)。我用我的华为荣耀8C手机自己拍摄了每张卡的约40张照片,照片中还有其他各种不需要的物体。然后,我又拍摄了约100张照片,其中有多张卡片。我知道我希望能够在卡片重叠时检测到它们,因此我确保在许多图像中卡片都重叠了。
您可以使用手机为对象拍照或从Google Image Search下载对象的图像。我建议总体上至少有200张照片。我用311张照片训练我的读卡器。
确保图像不是太大。它们每个应小于200KB,并且其分辨率不应大于720x1280。图像越大,训练分类器所需的时间就越长。您可以在此存储库中使用resizer.py脚本来减小图像的大小。
拥有所有需要的图片后,将其中的20%移至\ object_detection \ images \ test目录,然后将80%移至\ object_detection \ images \ train目录。确保\ test和\ train目录中都有各种各样的图片。
3b。标记图片
每个图片都标记完毕后,都会产生一个xml文件:
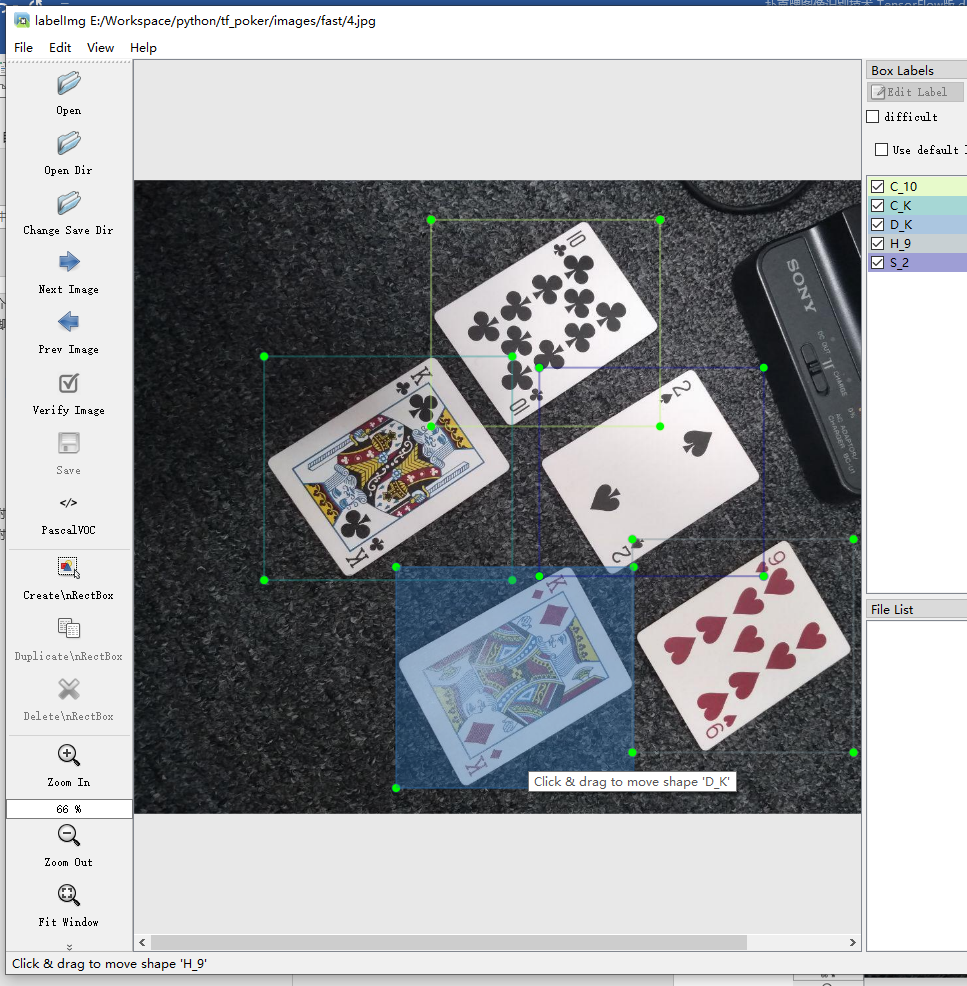
有趣的部分到了!收集了所有图片后,就该在每张图片中标记所需的对象了。LabelImg是标记图像的好工具,其GitHub页面上有关于如何安装和使用它的非常清晰的说明。
LabelImg GitHub链接
LabelImg下载链接
下载并安装LabelImg,将其指向\ images \ train目录,然后在每个图像中的每个对象周围绘制一个框。对\ images \ test目录中的所有图像重复该过程。这需要一段时间!
LabelImg保存一个.xml文件,其中包含每个图像的标签数据。这些.xml文件将用于生成TFRecords,它们是TensorFlow培训器的输入之一。标记并保存每个图像后,\ test和\ train目录中的每个图像都会有一个.xml文件。
4.生成训练数据
标记了图像之后,该生成TFRecords了,该记录用作TensorFlow训练模型的输入数据。本教程使用Dat Tran的Raccoon Detector数据集中的xml_to_csv.py和generate_tfrecord.py脚本,并做了一些细微修改以使用我们的目录结构。
首先,图像.xml数据将用于创建.csv文件,其中包含火车图像和测试图像的所有数据。从\ object_detection文件夹,在Anaconda命令提示符下发出以下命令:
(tensorflow1) C:\tensorflow1\models\research\object_detection> python xml_to_csv.py
这将在\ object_detection \ images文件夹中创建train_labels.csv和test_labels.csv文件。
接下来,在文本编辑器中打开generate_tfrecord.py文件。从第31行开始,用您自己的标签图替换标签图,其中为每个对象分配一个ID号。在步骤5b中配置labelmap.pbtxt文件时,将使用相同的编号分配。
例如,假设您正在训练分类器以检测篮球,衬衫和鞋子。您将在generate_tfrecord.py中替换以下代码:
def class_text_to_int(row_label):
if row_label == 'C_10':
return 1
elif row_label == 'C_K':
return 2
elif row_label == 'D_K':
return 3
elif row_label == 'H_9':
return 4
elif row_label == 'S_2':
return 5
else:
print('unknown label:', row_label)
return None
然后,通过从\ object_detection文件夹发出以下命令来生成TFRecord文件:
python generate_tfrecord.py --csv_input=images\train_labels.csv --image_dir=images\train --output_path=train.record
python generate_tfrecord.py --csv_input=images\test_labels.csv --image_dir=images\test --output_path=test.record
它们在\ object_detection中生成一个train.record和一个test.record文件。这些将用于训练新的对象检测分类器。
5.创建标签图并配置训练
培训之前的最后一件事是创建标签图并编辑培训配置文件。
5a。标签图
修改文件labelmap.pbtxt
item {
id: 1
name: 'C_10'
}
item {
id: 2
name: 'C_K'
}
item {
id: 3
name: 'D_K'
}
item {
id: 4
name: 'H_9'
}
item {
id: 5
name: 'S_2'
} 5b。配置培训
最后,必须配置对象检测训练管道。它定义了用于训练的模型和参数。这是进行训练之前的最后一步!
导航到C:\ tensorflow1 \ models \ research \ object_detection \ samples \ configs,然后将fast_rcnn_inception_v2_pets.config文件复制到\ object_detection \ training目录中。然后,使用文本编辑器打开文件。.config文件需要进行几处更改,主要是更改类和示例的数量,以及将文件路径添加到训练数据中。
对faster_rcnn_inception_v2_pets.config文件进行以下更改。注意:路径必须使用单个正斜杠(非反斜杠)输入,否则在尝试训练模型时TensorFlow将给出文件路径错误!此外,路径必须用双引号(“)而不是单引号(')。
- 第9行。将num_classes更改为要分类器检测的不同对象的数量。
- 第106行。将fine_tune_checkpoint更改为:
- fine_tune_checkpoint:“ C:/tensorflow1/models/research/object_detection/faster_rcnn_inception_v2_coco_2018_01_28/model.ckpt”
- 第123和125行。在train_input_reader部分中,将input_path和label_map_path更改为:
- input_path:“ C:/tensorflow1/models/research/object_detection/train.record”
- label_map_path:“ C:/tensorflow1/models/research/object_detection/training/labelmap.pbtxt”
- 第130行。将num_examples更改为\ images \ test目录中的图像数。
- 第135和137行。在eval_input_reader部分中,将input_path和label_map_path更改为:
- input_path:“ C:/tensorflow1/models/research/object_detection/test.record”
- label_map_path:“ C:/tensorflow1/models/research/object_detection/training/labelmap.pbtxt”
进行更改后保存文件。而已!培训工作已配置完毕,可以开始使用!
6.进行训练
从1.9版开始,TensorFlow已弃用“ train.py”文件,并将其替换为“ model_main.py”文件。我还无法使model_main.py正常工作(我遇到了与pycocotools相关的错误)。幸运的是,train.py文件在/ object_detection / legacy文件夹中仍然可用。只需将train.py从/ object_detection / legacy移至/ object_detection文件夹,然后继续执行以下步骤。
开始了!从\ object_detection目录,发出以下命令以开始训练:
python train.py --logtostderr --train_dir=training/ --pipeline_config_path=training/faster_rcnn_inception_v2_pets.config
如果一切设置正确,TensorFlow将初始化训练。实际训练开始之前,初始化过程可能最多需要30秒。
训练过程截图如下:
上图中的0.258 sec/step是每一步训练的时间长度,如果没有配置显卡,每一步大约需要2秒,配置显卡后的训练速度会提高8倍左右。可以看到显卡的负载很高,其中Cuda计算的负载满载了,显存也满载了:
训练的每一步都会报告损失。它会从高处开始,并随着训练的进行而越来越低。在我对Faster-RCNN-Inception-V2模型的培训中,它从大约3.0开始,然后迅速降至0.8以下。我建议允许您的模型进行训练,直到损失始终低于0.05,这将花费大约40,000步或大约2个小时(具体取决于您的CPU和GPU的功能)。注意:如果使用不同的模型,则损失数将有所不同。MobileNet-SSD的损失大约为20,应该接受培训,直到损失始终低于2。
您可以使用TensorBoard查看培训工作的进度。为此,请打开Anaconda Prompt的新实例,激活tensorflow1虚拟环境,更改为C:\ tensorflow1 \ models \ research \ object_detection目录,然后发出以下命令:
(tensorflow1) C:\tensorflow1\models\research\object_detection>tensorboard --logdir=training
这将在您的本地计算机上创建一个网页,网址为YourPCName:6006,可以通过网络浏览器进行查看。TensorBoard页面提供了信息和图表,它们显示了培训的进度。一个重要的图是损失图,它显示了分类器随时间的总体损失。
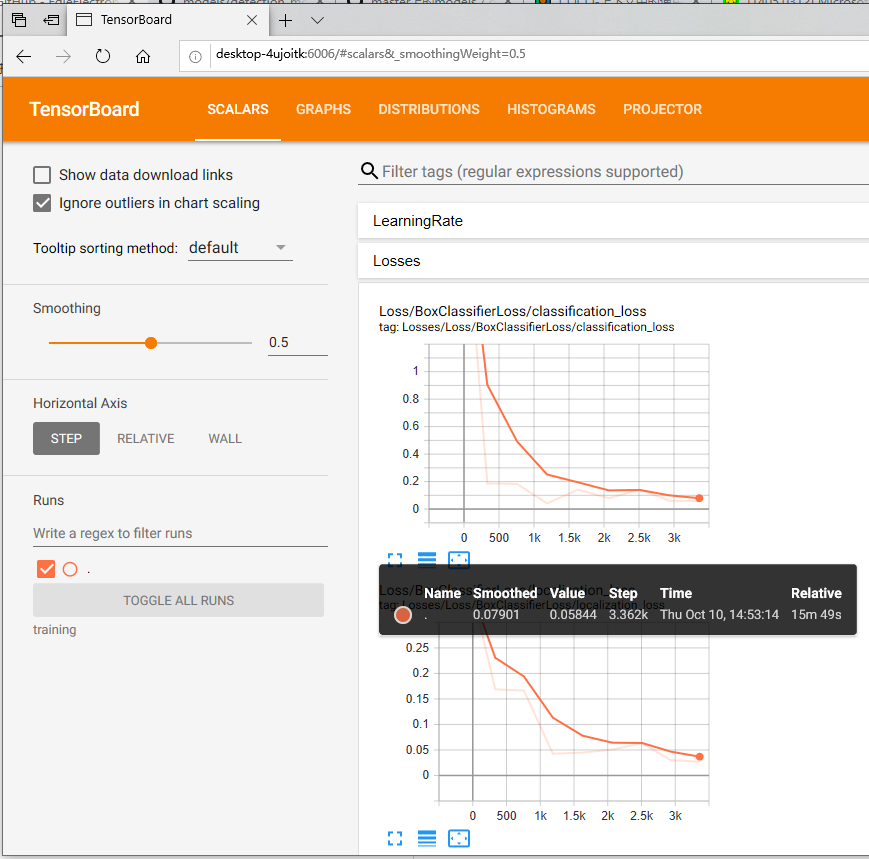
训练例程大约每五分钟定期保存一个检查点。您可以在命令提示符窗口中按Ctrl + C终止培训。我通常要等到保存检查点后才终止训练。您可以终止训练并稍后再开始,它将从最后保存的检查点重新开始。步骤数最多的检查点将用于生成冻结的推理图。
7.导出数据
既然训练已经完成,那么最后一步就是生成冻结的推理图(.pb文件)。从\ object_detection文件夹中,发出以下命令,其中“ model.ckpt-XXXX”中的“ XXXX”应替换为训练文件夹中编号最大的.ckpt文件:
python export_inference_graph.py --input_type image_tensor --pipeline_config_path training/faster_rcnn_inception_v2_pets.config --trained_checkpoint_prefix training/model.ckpt-XXXX --output_directory inference_graph
这将在\ object_detection \ inference_graph文件夹中创建Frozen_inference_graph.pb文件。.pb文件包含对象检测分类器。
8.使用新训练的物体检测分类器!
对象检测分类器已准备就绪!我已经编写了Python脚本来在图像,视频或网络摄像头feed上对其进行测试。
在运行Python脚本之前,您需要修改脚本中的NUM_CLASSES变量,使其等于要检测的类数。(对于我的Pinochle卡检测器,我要检测六张卡,因此NUM_CLASSES =6。)
要测试您的对象检测器,请将一个或多个对象的图片移动到\ object_detection文件夹中,然后更改Object_detection_image.py中的IMAGE_NAME变量以匹配图片的文件名。或者,您可以使用对象的视频(使用Object_detection_video.py),或仅插入USB网络摄像头并将其指向对象(使用Object_detection_webcam.py)。
要运行任何脚本,请在Anaconda命令提示符中键入“ idle”(已激活“ tensorflow1”虚拟环境),然后按Enter。这将打开IDLE,然后从那里可以打开任何脚本并运行它们。
如果一切正常,对象检测器将初始化约10秒钟,然后显示一个窗口,显示在图像中检测到的所有对象!
如果遇到错误,请查看附录:其中列出了在设置对象检测分类器时遇到的错误列表。您也可以尝试Google搜索错误。通常在Stack Exchange或GitHub上的TensorFlow的Issues中都有有用的信息。
TensorFlow对象检测API似乎是在基于Linux的操作系统上开发的,文档中给出的大多数指导都是针对Linux OS的。试图让Linux开发的软件库在Windows上运行可能具有挑战性。在尝试设置tensorflow-gpu以在Windows 10上训练对象检测分类器时,我遇到了很多麻烦。此附录列出了我遇到的错误及其解决方案。
1. ModuleNotFoundError:没有名为“ deployment”的模块或没有名为“ nets”的模块
当您尝试运行object_detection_tutorial.ipynb或train.py并且没有正确设置PATH和PYTHONPATH环境变量时,会发生此错误。通过关闭并重新打开Anaconda Prompt窗口退出虚拟环境。然后,发出“ activate tensorflow1”以重新进入环境,然后发出步骤2e中给出的命令。
您可以使用“ echo%PATH%”和“ echo%PYTHONPATH%”检查环境变量并确保它们设置正确。
另外,请确保已从\ models \ research目录运行以下命令:
setup.py build
setup.py install
2. ImportError:无法导入名称“ preprocessor_pb2”
ImportError:无法导入名称“ string_int_label_map_pb2”
(或其他pb2文件的类似错误)
当protobuf文件(在这种情况下为preprocessor.proto)尚未编译时,就会发生这种情况。重新运行步骤2f中给出的protoc命令。检查\ object_detection \ protos文件夹,以确保每个name.proto文件都有一个name_pb2.py文件。
3. object_detection / protos / .proto:没有这样的文件或目录
当您尝试运行
“protoc object_detection/protos/*.proto --python_out=.”
TensorFlow对象检测API安装页面上给出的命令。抱歉,在Windows上不起作用!复制并粘贴步骤2f中给出的完整命令。可能有一种更优美的方式来执行此操作,但我不知道它是什么。
4. TensorSliceReader构造函数失败:无法获取“文件路径” ...文件名,目录名称或卷标签语法不正确。
当训练配置文件(faster_rcnn_inception_v2_pets.config或类似文件)中的文件路径没有输入反斜杠而不是正斜杠时,将发生此错误。打开.config文件,并确保以以下格式给出所有文件路径:
“C:/path/to/model.file”
5. ValueError:试图将“ t”转换为张量,但失败。错误:参数必须为密集张量:range(0,3)-形状为[3],但需要[]。
问题出在models / research / object_detection / utils / learning_schedules.py当前
rate_index = tf.reduce_max(tf.where(tf.greater_equal(global_step, boundaries),
range(num_boundaries),
[0] * num_boundaries))
将list()包裹在range()周围,如下所示:
rate_index = tf.reduce_max(tf.where(tf.greater_equal(global_step, boundaries),
list(range(num_boundaries)),
[0] * num_boundaries))
参考:Tensorflow发行号3705
6. ImportError:DLL加载失败:找不到指定的过程。(或其他与DLL相关的错误)
发生此错误的原因是,您安装的CUDA和cuDNN版本与您使用的TensorFlow版本不兼容。解决此错误的最简单方法是使用Anaconda的cudatoolkit软件包,而不是手动安装CUDA和cuDNN。如果遇到这些错误,请尝试创建一个新的Anaconda虚拟环境:
conda create -n tensorflow2 pip python=3.5
然后,一旦进入环境,请使用CONDA而非PIP安装TensorFlow:
conda install tensorflow-gpu
然后从步骤2重新启动本指南(但是您可以跳过在步骤2d中安装TensorFlow的部分)。
7.在步骤2g中,笔记本计算机一直正常运行,没有错误,但末尾没有图片显示。
如果您运行了完整的程序,但没有出现任何错误,但仍然没有出现带标签的图片,请尝试以下操作:进入object_detection / utils / visualization_utils.py并注释掉包含matplotlib的第29和30行附近的import语句。然后,尝试重新运行程序。
· 识别准确率较低,容易识别错误。但优点是可以识别出叠加的扑克。(在训练素材方面可以优化,能明显提高识别准确率)。
· 有一定的几率程序加载过程中卡死。
· 有一定的几率读取到视频为花屏,导致无法继续识别。
· 识别扑克耗时长。每识别一帧图像需要0.15秒左右的时间,每秒可以识别6帧图像。
· 训练耗时长。配了显卡需要训练1小时,不配置显卡需要8-10小时.
· 用到的技术栈较多,各技术栈在很多地方会报错。解决这些错误的网上资料很多坑。
· 设置显卡编译过程比较曲折。(如果不配置显卡,训练时间会长10倍左右。)
· 业务层可修改的代码才十几行。具体图像识别的算法封装得很深,不好修改。
· 图像训练过程步骤比较多。许多环节需要手动修改配置,容易出错。
https://blog.csdn.net/qq_24946843/article/details/88181686
https://github.com/EdjeElectronics/TensorFlow-Object-Detection-API-Tutorial-Train-Multiple-Objects-Windows-10
https://www.tensorflow.org/tutorials?hl=zh_cn
https://github.com/EdjeElectronics/TensorFlow-Object-Detection-API-Tutorial-Train-Multiple-Objects-Windows-10